



Life-cycle Planning — Design and Calibration for Ultimate Efficiency
The ultimate power of Big Data technologies relies on the implementation of new strategies. Unlike a traditional engine calibration process, in which only calibration test data and model simulation data are used, multiple source data introduced into the adaptive engine calibration process contributes to efficiency and cost reduction.

Extending the life cycle of products in the off-highway industry provides benefits to OEMs, purchasers, end users, and general society. Before Big Data technologies were developed recently, there were many guidelines and case studies regarding remanufacturing processes.
However, the full utilization of these benefits depends on the successful parts salvage with low cost. If a component cannot be separated into the consumable and durable parts, more cost will be incurred during the remanufacturing process.
Many design techniques have been applied to traditional technologies to improve remanufacturability of components, subsystems, systems, and vehicles. For example, special designs will allow wear to occur on the top edge of piston rings instead of linens. In this way, linens and pistons can be easily reprocessed during remanufacturing, while piston rings are replaced. However, a traditional remanufacturing process is disconnected from the product calibration process. A rule of thumb is used to estimate the wearing level of components without life-cycle wearing data support.
Adaptive calibration
The engine calibration process dramatically affects product life-cycle planning as it is the final step in determining engine performance and emissions. The process has several characteristics. First, an engine calibration solution can be easily adjusted to validate the optimized solution on one sample engine, but it is difficult to validate the proposed solution on the engine population. Second, the engine calibration is focused on overall system performance, and subsystems’ calibration is assumed to bring all subsystems’ performance to the nominal value.

When an engine control module (ECM) notices a change of speed and load, control parameters are interpolated according to control maps. These control maps are created in the engine calibration process and will be used for all engines of the same family. The goal of calibration is to locate a combination of ECM parameter values, so that both engine performance requirements and emissions requirements are met.
According to all theoretical studies and calibration tests, start of ignition is a critical parameter to control the NOx emissions; hence, the injection timing for diesel engines and spark ignition timing for gasoline engines are determined during the typical engine calibration process. These calibration tests are based on one engine sample or several engine samples.
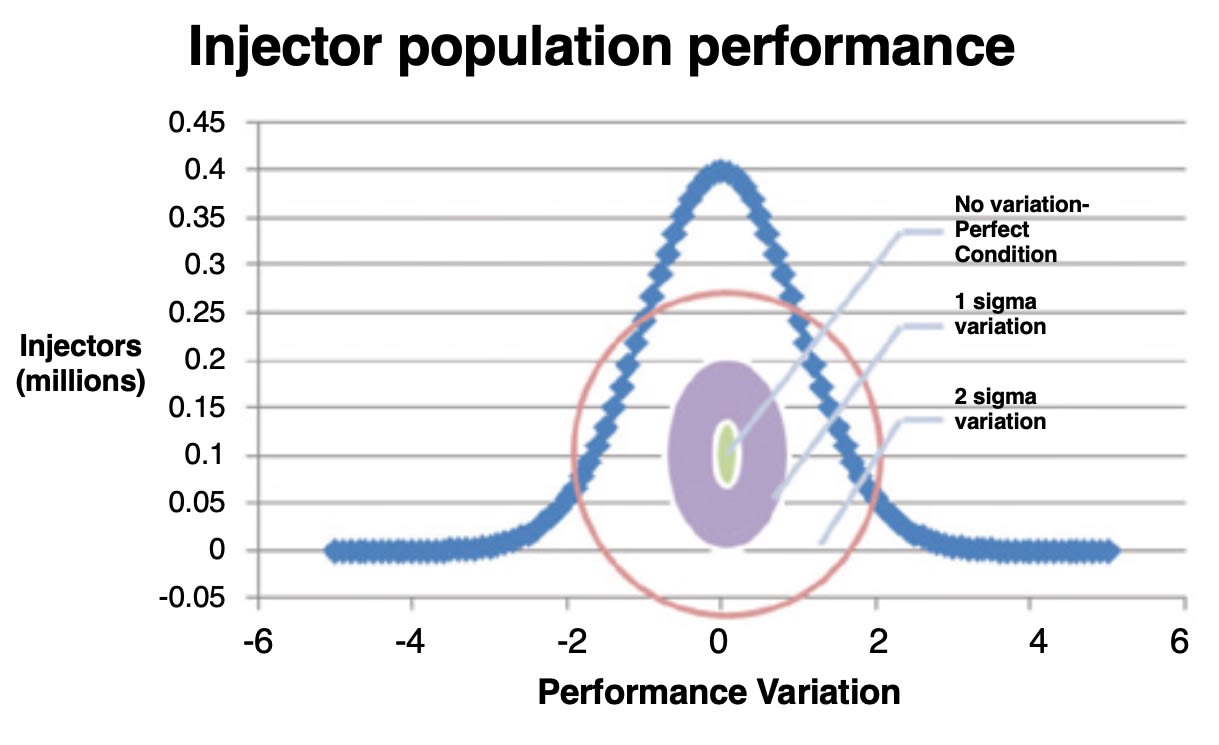
Since there are unavoidable manufacturing variations, other procedures will be adopted to tune fuel quantities for each engine to meet power requirements. Subsystems’ manufacturing tolerance impacts final engine performance and calibration. For example, injectors could deliver different fuel quantities at the same ECM parameters. Injectors’ end-of-line tests are conducted according to certain criteria. Trim factors are also used to bring each injector’s performance close to the nominal values.
The start of diesel fuel injection is fixed to ensure emissions compliance for all engines in the same family. Fuel quantities and injection duration can be tuned for different injectors and diesel engines to compensate manufacturing variation. This practice could lead to a different end of injection (EOI) for different diesel engines. It is well known that there is a relationship between the EOI and soot rate in oil for diesel engines. The soot rate in oil impacts components wearing of diesel engines. Due to the different EOI, different engines actually have different soot percentage in oil during normal engine working cycles. These small differences accumulate through whole engine working life, and it will finally lead to different wearing levels at the end of a product’s life.
Given the above scenario, each engine actually has its own wearing process, although OEMs typically suggest the common oil life and maintenance schedules for all engines that belong to the same engine model. Dealers have already utilized maintenance logs for each vehicle to customize their service plans. However, the detailed ECM control and tuning information are not always available to dealers.
All subsystems’ and engines’ calibration and tuning information have been available for decades, and there are also many empirical models to estimate the oil soot and engine wear based on engine cycles and ECM control parameters. However, OEMs have rarely used them to customize remanufacturing design and salvage techniques for each engine. The reason is that too many factors affect the effectiveness to utilize the calibration and tuning information, such as vehicle working cycles and repairs or premature replacements. Some useful information is generated from end users’ work cycle logs, and others are from OEMs, dealers, and independent repair shops. All kinds of information are generally heterogeneous in terms of data structure, posing huge challenges for traditional data abstraction and the data mining process.
Big Data is watching
Without the help of Big Data technologies, traditional life-cycle planning is typically based on statistical analysis for failed parts. The research aims to develop a methodology for designing products that can be more easily remanufactured. The focus is to analyze the root causes for the engine parts that cannot be reused or remanufactured. These parts are referred to the parts “that will enter the remanufacturer’s waste stream. Analysis of this waste stream will identify barriers to the reuse of parts.”
As for the engine remanufacturing process, emissions compliance also needs to be considered. The boring process and machining process could easily change the combustion chamber geometry and valve timing. The compression ratio and volumetric efficiency could be easily affected.
In previous research work, a strict process was defined to ensure that an engine can meet emissions standards for the year of the original production. However, tight tolerances and extra validation both add cost to the remanufacturing process. The emissions requirements can be easily met by tuning a calibration solution when engine physical parameters have slight changes.
It is not cost-effective for OEMs or remanufacturers to perform thorough engine tests and repopulate all control maps. The solution is to reuse the previous data that OEMs generated during the normal engine calibration process.
As off-highway equipment has gotten more sophisticated, many microprocessors have been installed to perform certain tasks. As for internal-combustion engines, sometimes more than one microprocessor is used for both engine control and aftertreatment control. Due to the fast upgrading pace of electronic modules, OEMs also need to ensure the availability of compatible electronic modules during engine service life.
Microprocessor suppliers typically will suspend low-volume product manufacturing or charge very high cost to supply low-volume products. Remanufacturing is one method to provide a cost-effective solution to extend electronic modules’ life. It is desired for OEMs or remanufacturers to know whether the original components have experienced a high cycle rate or a low cycle rate. To get this useful information, a cycle counter has to be developed first.
When more engine and vehicle sensors are placed onboard, more information becomes available. With the help of Big Data technologies, life-cycle planning can bring more benefits to OEMs and customers than traditional recycling or remanufacturing processes.
First level of adaptive calibration

The first level to utilize adaptive calibration is to integrate each subsystem’s optimum range into the final calibration. For example, all major engine components’ EOL (end of line) test results can be introduced in the final engine calibration phase. Variation of components can be better understood and handled during the final engine calibration. Some variations can lead to the increase of brake-specific NOx (BSNOx) emissions, while others could reduce BSNOx emissions.
The impacts on engine emissions due to the variations of different major components such as injectors, turbochargers, and manifolds could actually offset each other. The traditional engine calibration process is based on the assumption that all variations linearly accumulate in the worst case scenario.
With Big Data technologies, a series of engine calibration solutions will be concurrently developed. At the final engine hot test, the most suitable engine calibration solution will be chosen according to both components EOL test results and engine hot-test results. Another example is given below to demonstrate the first level of the adaptive calibration applied to diesel engines.
Exhaust gas recirculation (EGR) can dramatically reduce BSNOx emissions. In the traditional engine calibration process, a sample engine is tested in an engine lab, and a calibration engineer determines the desired EGR flow quantity for engine operation conditions according to the emissions results. The feedback controller adjusts the EGR flow according to the desired quantity. The actuator is typically a valve, and position adjustment of the EGR valve will physically increase or decrease the EGR flow.
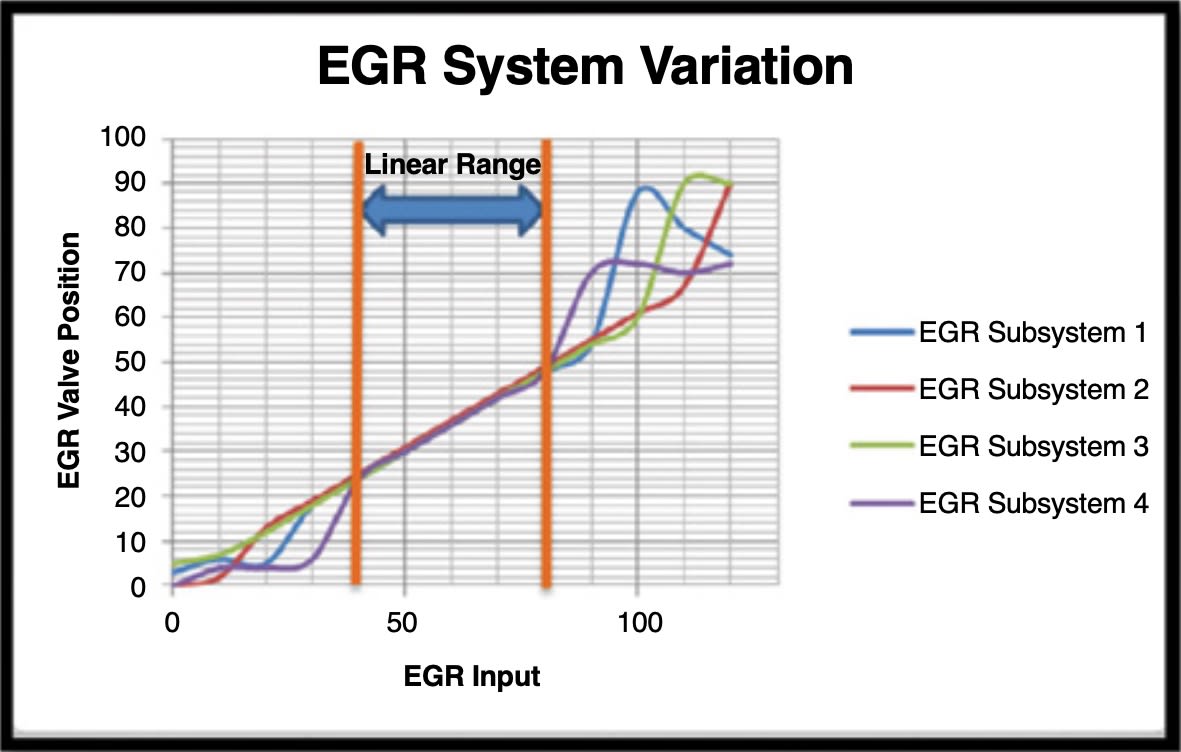
In industry, a typical Proportional-Integral (PI) controller is implemented for the EGR feedback control. PI controllers work well in linear dynamic systems in nature. However, a modern diesel engine is a complicated, non-linear system. To precisely control feedback calibration parameters, desired values need to be in a linear operation region for PI controllers.
Due to the manufacturing variation, EGR control subsystems could have slightly different responses. In the traditional engine calibration process, limits are set up for the EGR subsystem first. Valid engine calibration solutions will only use values within the EGR subsystems’ limits. The limits are based on variation concerns regarding different EGR systems’ performance out of linear range.
Since each EGR subsystem has EOL test results, the information of linear range for each EGR subsystem is theoretically available. The traditional engine calibration process uses a rule of thumb to determine the safety margin of EGR subsystem.
With the help of Big Data technologies, subsystems EOL test results can be reused in the engine calibration process. For example, different linear ranges could be used according to the real EGR subsystems’ performance in the final engine calibration. The process makes a calibration solution more customized for an individual engine. Both engine performance and reliability can be improved with more accurate control tactics.
Second level of adaptive calibration
The second level to utilize the adaptive calibration is to adaptively adjust the final calibration of products according to their working environment. The traditional calibration process is performed under well-defined boundary conditions. For example, the traditional engine calibration process will first define restriction conditions of an engine.
Different vehicles can have different working environments and the working environments of vehicles can also change from time to time. Traditional calibration solutions are focused on protecting engines in the worst scenario, and the calibration solutions typically lack the self-adjusting capability once the maps, gains, and ECM tune parameters are determined.
Big Data technologies can utilize the data from engine and vehicle sensors to monitor the performance of engines and vehicles. The information from real-time analysis can provide huge value for design engineers, calibration engineers, product service staff, and even end users.
Big Data technologies can combine equipment and application information from multiple sources. Thorough comparisons and business intelligence tools can be used to reveal potential value for both OEMs and customers.
For example, an engine can select an optimal calibration solution for a specific working environment. With the help of Big Data technologies, more than one engine calibration solution can be developed during the engine calibration process. All calibration solutions can meet emissions requirements. When boundary conditions are different, the optimum solution could also change.
In addition to boundary conditions, an initial condition of engine operating status impacts engine emissions as well. With more aftertreatments used in modern diesel engines, repeatability of measurement becomes a challenge in the diesel engine calibration process. Similar challenges were witnessed when aftertreatments were added to gasoline engines. Two factors contribute to the fluctuation of measurement: Low emissions levels of modern engines enlarge the percentage variation in measurement, and aftertreatment catalyst sensitivity to temperature and reactants’ concentration is a driving cause for the fluctuation of measurement in a typical transient test.
Previous researchers optimized the preconditioning tests to improve measurement repeatability. Three preconditioning patterns were tested in their research, and, according to their testing results, “it was found that performing stoichiometric preconditioning before each test was most effective in improving measurement repeatability.”
An identical initial condition is the key to improved repeatability of measurement in an engine with aftertreatments. Many emissions regulations define a preconditioning process for certification cycles according to previous research. Since Big Data technologies provide measures to monitor engine operating status continuously, both boundary conditions and initial conditions could be retrieved from Big Data infrastructure.
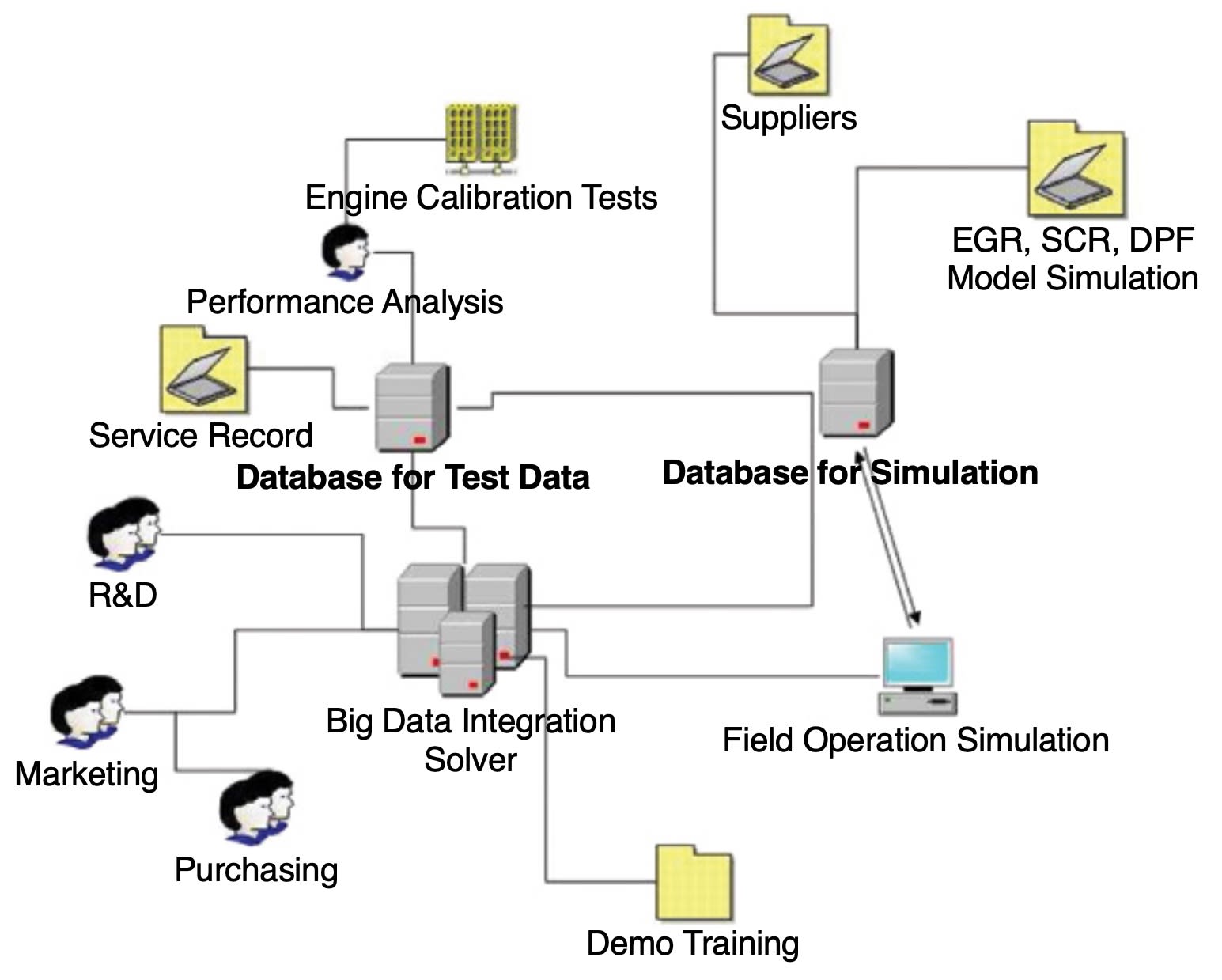
Real-time data analysis expands engine calibration scope. Typical input data for a traditional engine calibration process are engine calibration tests and simulation data. In the adaptive engine calibration process, after-sales service data, external feedback, validation data, manufacturing process data such as subsystems’ EOL tests, and engine hot tests can be taken into consideration as well. With the expanded scope, the engine calibration process serves as an integration knot for the Continuous Product Improvement (CPI) process.
The expanded scope of the adaptive engine calibration process results in more benefits for both automotive OEMs and customers:
- Engine conditions can be monitored and compared to their normal values that are derived from calibration and histogram data. High-low limits or other statistical checking can be implemented to prevent major components failure.
- Engine conditions can be monitored and compared to similar engines under similar field conditions. Big Data technologies enable heterogeneous data mining. Normal state can be dynamically defined by the average performance of all similar engines. Factors can be carefully checked to reveal the driving causes for downtime or inefficiency. Big Data technologies can automate this kind of analysis and provide reports to both OEMs and end users.
- Engine conditions can be monitored and compared to industry standards, simulation models, and pilot research data. OEMs can utilize the comparison results to perform the pattern recognition study for CPI projects or to support next-generation NPI projects.
- Big Data technologies facilitate the tracking of calibration solutions loaded on each individual vehicle. OEMs can manage the freedom degree for the calibration adjusting. Onboard self-adaptive calibrations are transparent to end users and have the most freedom. OEMs can also let only dealers or only their product support team authorize calibration adjusting.
Parallel RDBMS (relational database management system) infrastructure is also suitable to support the adaptive calibration process. The biggest challenge for parallel RDBMS is data variety when external feedbacks are included in the adaptive calibration process. MapReduce and Distributed File Systems (DFS) provide better capability to load heterogeneous data, such as sensor data, web forms input, web blogs, and call surveys.
However, it takes more time for MapReduce and DFS to perform optimization analysis compared to RDBMS. RDBMS have been fully developed to perform structured data analysis. As for the adaptive calibration, optimization is the core calculation. The advantages of RDBMS outweigh their weakness in loading unstructured data.
This article is based on SAE International technical paper 2014-01-2410 by Xinyu Ge and Jonathan Jackson, Caterpillar Inc.
More From SAE Media Group
Off-Highway Engineering
Development Trends for Heavy Engines
Off-Highway Engineering
Cummins Unveils New B7.2 Diesel Engine
Off-Highway Engineering
Heavy-Duty Engine Design
Off-Highway Engineering
The Complicated Future of Off-Highway Engines
Automotive Engineering
Cooled EGR Shows Benefits for Gasoline Engines
Off-Highway Engineering
Advances for Off-highway Engine Design
Off-Highway Engineering
Mahle, Liebherr Develop Active Pre-Chamber for Hydrogen ICE
Off-Highway Engineering
Expediting Engine Design
Off-Highway Engineering
Off-highway Calibration Challenges — Big and Complex
Automotive Engineering
Achates Aims at 2025 Light-truck Power
Off-Highway Engineering
Iveco Pursues Natural Gas in Stralis NP Models
Off-Highway Engineering
Delphi Injects Life into Diesel
Automotive Engineering
2015 Engines Ride a Technology Tidal Wave
Automotive Engineering
Future ICEs: What Comes After 2025?
Off-Highway Engineering
Miserly Power Systems
Automotive Engineering
'Reman' Engine Market Steady, but Complexity Challenges Production Efficiency
Automotive Engineering
New Engines 2016
Automotive Engineering
Balancing GDI Fuel Economy and Emissions
Off-Highway Engineering
Rotary SI/CI Combustion Engines: A Thing of the Future?
Automotive Engineering
JLR's All-New 2015 Modular Engines Feature Roller-Bearing Cams, Balance Shaft
Automotive Engineering
Mazda Plots Wankel-powered Range Extenders, HCCI Mild Hybrids
Off-Highway Engineering
Diesel Isn’t Dead
Automotive Engineering
Spark of Genius
Off-Highway Engineering
DEF Delivery Modeling for SCR Systems
Automotive Engineering
Audi's New V6 Diesel to Feature Electric Turbocharging, New NOx Technology
Off-Highway Engineering
Waste Heat Recovery for the Long Haul
Off-Highway Engineering
FEV Simplifies Off-Highway Electrification
Off-Highway Engineering
Solving Problems and Seeking Big Ideas for Commercial Vehicles
Automotive Engineering
The Inside Story on Thermal Management
Automotive Engineering
Transforming Propulsion with Tula’s Digital-Control Magic
Top Stories
INSIDERManufacturing & Prototyping
![]() How Airbus is Using w-DED to 3D Print Larger Titanium Airplane Parts
How Airbus is Using w-DED to 3D Print Larger Titanium Airplane Parts
INSIDERManned Systems
![]() FAA to Replace Aging Network of Ground-Based Radars
FAA to Replace Aging Network of Ground-Based Radars
NewsTransportation
![]() CES 2026: Bosch is Ready to Bring AI to Your (Likely ICE-powered) Vehicle
CES 2026: Bosch is Ready to Bring AI to Your (Likely ICE-powered) Vehicle
NewsSoftware
![]() Accelerating Down the Road to Autonomy
Accelerating Down the Road to Autonomy
EditorialDesign
![]() DarkSky One Wants to Make the World a Darker Place
DarkSky One Wants to Make the World a Darker Place
INSIDERMaterials
![]() Can This Self-Healing Composite Make Airplane and Spacecraft Components Last...
Can This Self-Healing Composite Make Airplane and Spacecraft Components Last...
Webcasts
Defense
![]() How Sift's Unified Observability Platform Accelerates Drone Innovation
How Sift's Unified Observability Platform Accelerates Drone Innovation
Automotive
![]() E/E Architecture Redefined: Building Smarter, Safer, and Scalable...
E/E Architecture Redefined: Building Smarter, Safer, and Scalable...
Power
![]() Hydrogen Engines Are Heating Up for Heavy Duty
Hydrogen Engines Are Heating Up for Heavy Duty
Electronics & Computers
![]() Advantages of Smart Power Distribution Unit Design for Automotive...
Advantages of Smart Power Distribution Unit Design for Automotive...
Unmanned Systems
![]() Quiet, Please: NVH Improvement Opportunities in the Early Design...
Quiet, Please: NVH Improvement Opportunities in the Early Design...